
產品介紹
Hologres 是阿里云自研一站式實時數倉,統一數據平臺架構,將OLAP查詢、即席分析、在線服務、向量計算多個數據應用構建在統一存儲之上,實現一份數據,多種計算場景。
V2.1 版本簡介
新增彈性計算組實例,解決實時數倉場景下分析性能、資源隔離、高可用、彈性擴縮容等核心問題,同時新增多種用戶分析函數與實時湖倉Paimon格式支持,COUNT DISTINCT優化顯著提升查詢效率。
升級說明:Hologres支持熱升級,跨大版本升級建議停機升級。
彈性計算組(warehouse)構建高可用實時數倉
功能說明:
Hologres彈性計算組(warehouse)采用Shared Data 架構,存儲共用一份,計算資源分解為不同的計算組(Warehouse),每個計算組可獨立彈性擴展,計算組之間共享數據、元數據。
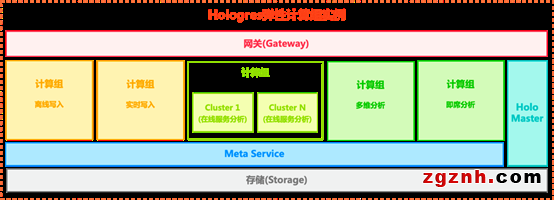
應用場景:
彈性計算組有多種使用方式,用戶可以實現高可用、負載隔離與降本,并顯著提升故障恢復速度及使用易用性。
● 隔離與高可用:計算組之間物理隔離,不同部門業務之間實現讀讀隔離、寫寫隔離、讀寫隔離,同時避免計算組之間的相互影響,減少業務抖動。
● 成本與彈性:存算分離,存儲共享一份,計算組可動態熱擴縮容,顯著降低成本。
● 易用性:對應用只暴露一個Endpoint,新增與銷毀、故障實例切換等操作通過簡單SQL即可快速實現,實現故障自動路由。
其他核心能力
實時湖倉新增Paimon格式
功能說明:
Hologres實時湖倉能力在之前版本支持ORC、Parquet、CSV、SequenceFile、HUDI、Delta、Parquet等多種格式,V2.1 版本新增Paimmon格式,Apache Paimon是流批統一的湖存儲格式,支持高吞吐的寫入和低延遲的查詢,促進數據在數據湖上真正實時的流動,并為用戶提供基于湖存儲的實時離線一體化的開發體驗。
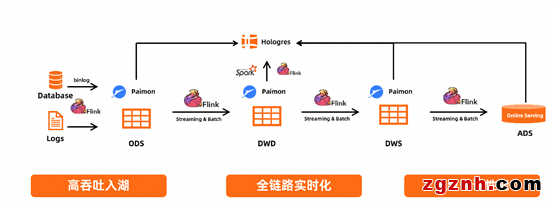
應用場景:
Flink +Paimon+ Hologres 實時湖倉。基于Flink將數倉以Paimon這種 Table Format 形式在湖上構建,上層可以使用 Flink進行流計算,使用 Hologres 對所有層次做統一的OLAP查詢或者是最上面的ADS層做在線分析。方案中Paimon可以實現高吞吐的入湖,Flink 可以實現全鏈路的實時計算,Hologres 可以實現高性能的OLAP查詢,所以整個鏈路從實時性、時效性、成本幾個方面都可以取的比較好的平衡。
向量計算新增計算巢方案,5分鐘拉起企業級知識庫
功能說明:
基于計算巢能力,5分鐘一鍵拉起Hologres向量計算+PAI部署大模型所需資源,直接通過WebUI與示例數據,進行大模型+向量計算對話。
應用場景:
企業級對話知識庫構建。將專屬行業知識向量化處理后,存儲到向量引擎,通過向量計算結合大模型推理求解,輸出專屬領域準確答案,減少大模型問答幻覺,完成實時知識更新并提高問答速度。
自動優化CountDistinct,提升查詢效率
功能說明:
Hologres從V2.1版本開始,針對Count Distinct場景做了非常多的性能優化(包括單個Count Distinct、多個Count Distinct、數據傾斜、SQL沒有Group By字段等場景),無需手動改寫成UNIQ,即可實現更好的性能。
應用場景:
在PV、UV計算等場景提升精確去重查詢效率

對比V2.1與V2.0版本,V2.1在單條及多條Count Distinct的內存消耗、CPU使用、耗時上都有顯著差異。

優化Runtime Filter能力,顯著提升Join效率
功能說明:
Hologres V2.0版本支持1個join字段的Runtime Filter,V2.1開始支持多字段Join的Runtime Filter。在Join過程中,Hologres根據build端的數據特征和分布以及最終Join的數據量和原始掃描數據量,自動對probe端的數據進行裁剪,從而減少對probe端的數據掃描和Shuffler,以此來提升Join性能。
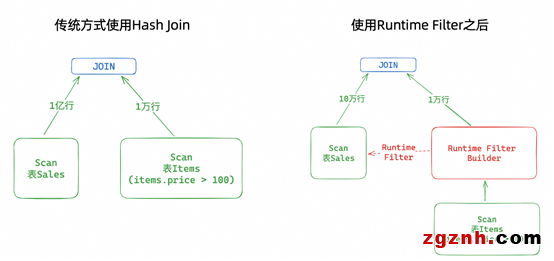
應用場景:
多字段join時,自動優化大小表join效率,如以下示例SQL,V2.1版本可以提升30%-100%查詢速度。

Runtime Filter是自動觸發的能力,無需手動開啟。觸發條件如下:
.probe端的數據量在100000行及以上。
.掃描的數據量比例:build端 / probe端 <= 0.1(比例越小,越容易觸發Runtime Filter)。
.Join出的數據量比例:build端 / probe端 <= 0.1(比例越小,越容易觸發Runtime Filter)。
新增漏斗、留存、路徑等函數,簡化用戶行為分析
功能說明:
用戶漏斗分析、留存分析、路徑分析是常見的用戶行為數據分析場景,Hologres新增漏斗、留存、路徑函數,可以幫助用戶更加簡單、高效地完成行為分析。
應用場景:
用戶漏斗分析,計算每個階段行為轉化率。Hologres原生支持漏斗函數,也支持區間漏斗函數,這樣不僅可以看到每個階段的漏斗結果,也可以分組展示漏斗的結果,不需要寫額外的各種擴展語法。

用戶留存分析,計算近3天、7天用戶等留存。Hologres支持留存函數和留存擴展函數,方便業務可以高效的分析產品留存率,助力進一步業務決策。

用戶路徑分析,計算用戶產品使用路徑分布情況。Hologres路徑函數可以基于事件,統計用戶訪問行為的流入留出,快速搭建用戶路徑桑基圖。
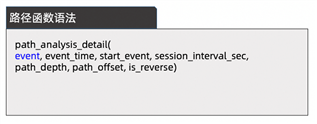
BSI+RB函數助力高效畫像分析
功能說明:
Hologres原生支持Roaring Bitmap函數,將用戶ID構建成Bitmap實現屬性標簽的快速分析;同時在2.1版本開始支持BSI函數,通過BSI的高效壓縮和切片索引,實現行為標簽的高效分析,同時在查詢時可以通過二進制原理和Roaring Bitmap交并差運算進行快速計算,支持對高基數行為標簽的壓縮存儲和低延遲查詢,從而實現“屬性標簽”和“行為標簽”的高效聯動分析。
應用場景:
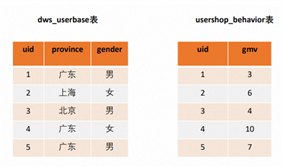
通過BSI函數+RB函數實現高效的行為分析與畫像分析。例如在一張用戶屬性表,一張用戶收入表,表結構如下:
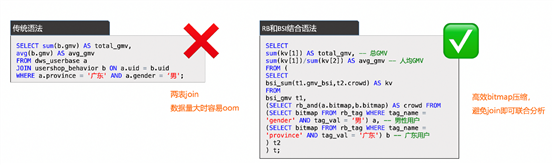
若要計算出“廣東、男用戶的GMV總和”,傳統的Join語法,數據量大時容易OOM,通過高效bitmap壓縮,避免join即可聯合分析。
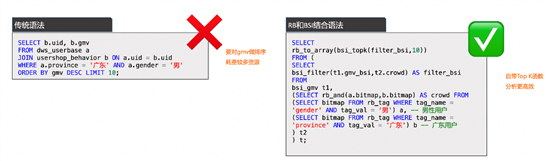
若要計算出“昨日廣東男用戶消費金額Top K”,傳統語法對GMV排序要消耗大量資源,BSI+RB自帶TopK函數,分析更高效。
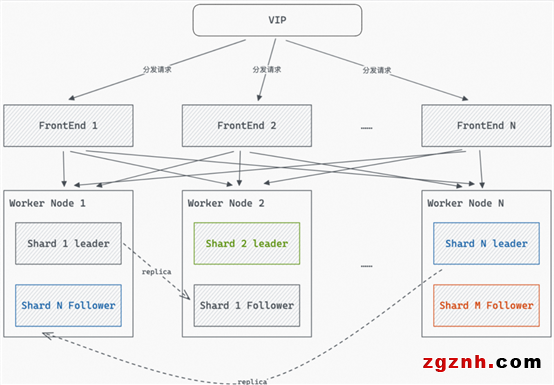
支持單實例Shard多副本,提升吞吐量,實現查詢高可用
功能說明:
單實例Shard多副本是Hologres一直Beta中的能力,在V2.1版本正式發布,可以實現單實例內高可用及負載均衡擴吞吐場景,可容忍部分機器故障及熱點不均衡問題。
應用場景:
多副本高吞吐場景
小部分Worker計算資源使用率很高,其他Worker很低,有可能是查詢不均導致的,此時增加Shard的副本數量,使更多的Worker上有Shard的副本,有效提高資源利用率和QPS。
多副本高可用場景
因為單Shard Failover時導致查詢不可用情況,增加副本數量后,某個worker發生故障時,由于仍存在完整的Shard副本,實例可以繼續。
結合DataWorks增強數據同步、血緣、地圖、傳輸加密等能力
功能說明:
Hologres與DataWorks深度集成,在過去的MySQL、Oracle、PolarDB、SQLServer等數據源的基礎上,V2.1版本新增支持ClickHouse整庫全量、ADB整庫同步、Kafka實時同步到Hologres。同時在DataWorks中可以采集Hologres元數據,查看Hologres表血緣和字段血緣信息。
更多完整功能列表請查看Hologres V2.1功能發布記錄
 粵公網安備 44030702001206號
粵公網安備 44030702001206號