|
近日,阿里云人工智能平臺PAI的論文《Llumnix: Dynamic Scheduling for Large Language Model Serving》被OSDI '24錄用。論文通過對大語言模型(LLM)推理請求的動態調度,大幅提升了推理服務質量和性價比。 Llumnix是業界首個能靈活在不同模型實例間重新分配請求的框架;并且,實驗表明,與最先進的LLM服務系統相比,Llumnix請求尾延遲時間劇減超過10倍,將高優先級請求的速度提高了1.5倍,并在實現類似尾部延遲的同時,成本降低為原先的64%。
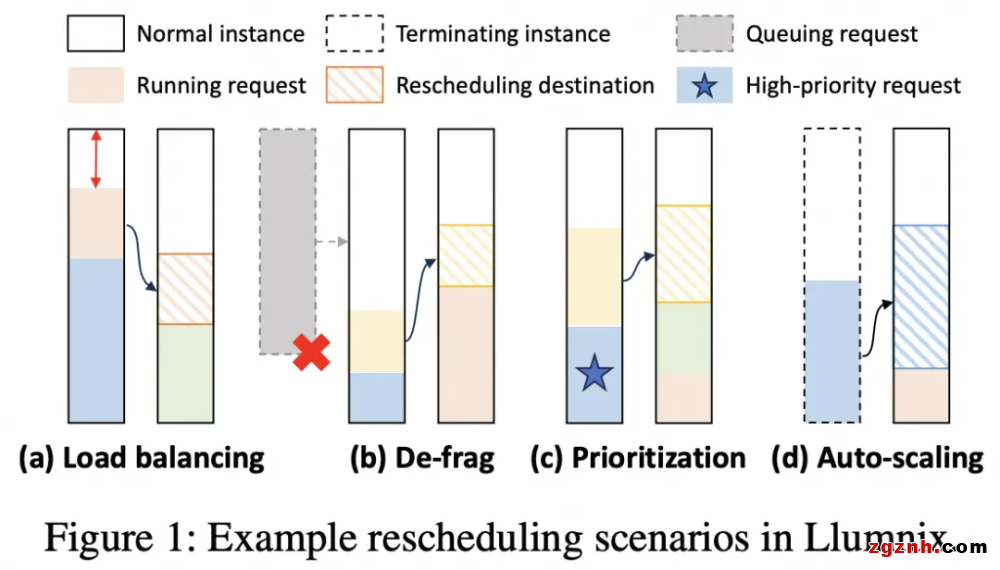
OSDI是操作系統及分布式系統領域的旗艦級會議,OSDI與其姊妹會議SOSP長期以來對系統領域發展起著深刻的推動作用,在學術和工業界均有巨大影響力。OSDI/SOSP上曾誕生了許多影響深遠的論文和系統,如GFS、MapReduce、BigTable等經典的分布式系統,以及如TensorFlow、TVM、vLLM等在人工智能領域產生深遠影響的系統。 此次入選意味著阿里云人工智能平臺PAI在大模型推理領域持續引領業界方向,獲得了國際學者的認可,展現了中國機器學習系統技術創新在國際上的競爭力。 自ChatGPT這一顛覆性產品問世以來,生成式大語言模型(LLM)技術迎來了堪稱日新月異的發展,短短一到兩年時間我們已經見證了一系列大模型及產品的誕生和應用。LLM推理服務也因此成為LLM不斷產品化進程中的關鍵技術支撐。然而LLM推理的請求及其執行呈現高度的差異性、動態性和不可預測性,這些特性給現今的推理服務系統帶來了一系列挑戰,大大限制了LLM推理服務的效率。 Llumnix是阿里云PAI團隊研發的LLM推理動態調度框架,旨在利用調度的動態性來化解由請求的動態性帶來的種種挑戰。Llumnix是一個支持在多個模型實例之間對請求進行運行時重調度的框架,這一重調度能力使得Llumnix可以根據請求狀態的動態變化對調度決策進行適應性調整,并以此實現了如負載均衡、碎片整理、請求優先級等一系列調度特性和優化(如下圖)。通過在LLaMA系列模型上的實驗,初步展示了動態調度的潛力,如大幅降低延遲,加速高優先級請求,以及降低服務成本等。
阿里云人工智能平臺PAI團隊對Llumnix進行了產品化研發,并已開源(Github地址:https://github.com/AlibabaPAI/llumnix)。當前版本的Llumnix支持vLLM為后端推理引擎,可自動化拉起多實例vLLM服務,并在多實例之間進行請求調度及重調度。Llumnix保持了與vLLM非常相似的用戶接口,從而以盡可能平滑和透明的方式加持在已部署的vLLM服務之上。目前,開源版本的Llumnix處于alpha狀態,仍在積極研發和迭代中。歡迎您的試用和反饋!后續Llumnix將與阿里云人工智能平臺PAI自研的BladeLLM推理引擎、PAI-EAS模型在線服務等產品深度結合,形成一體化的高性能LLM推理套件,并集成進入PAI靈駿智算服務產品,助力企業和個人開發者完成云上大語言模型服務的創新。 論文信息 論文標題:Llumnix: Dynamic Scheduling for Large Language Model Serving 作者:孫彪,黃梓銘,趙漢宇,肖文聰,張欣怡,李永,,林偉 論文地址:https://www.usenix.org/conference/osdi24/presentation/sun-biao |


 粵公網安備 44030702001206號
粵公網安備 44030702001206號